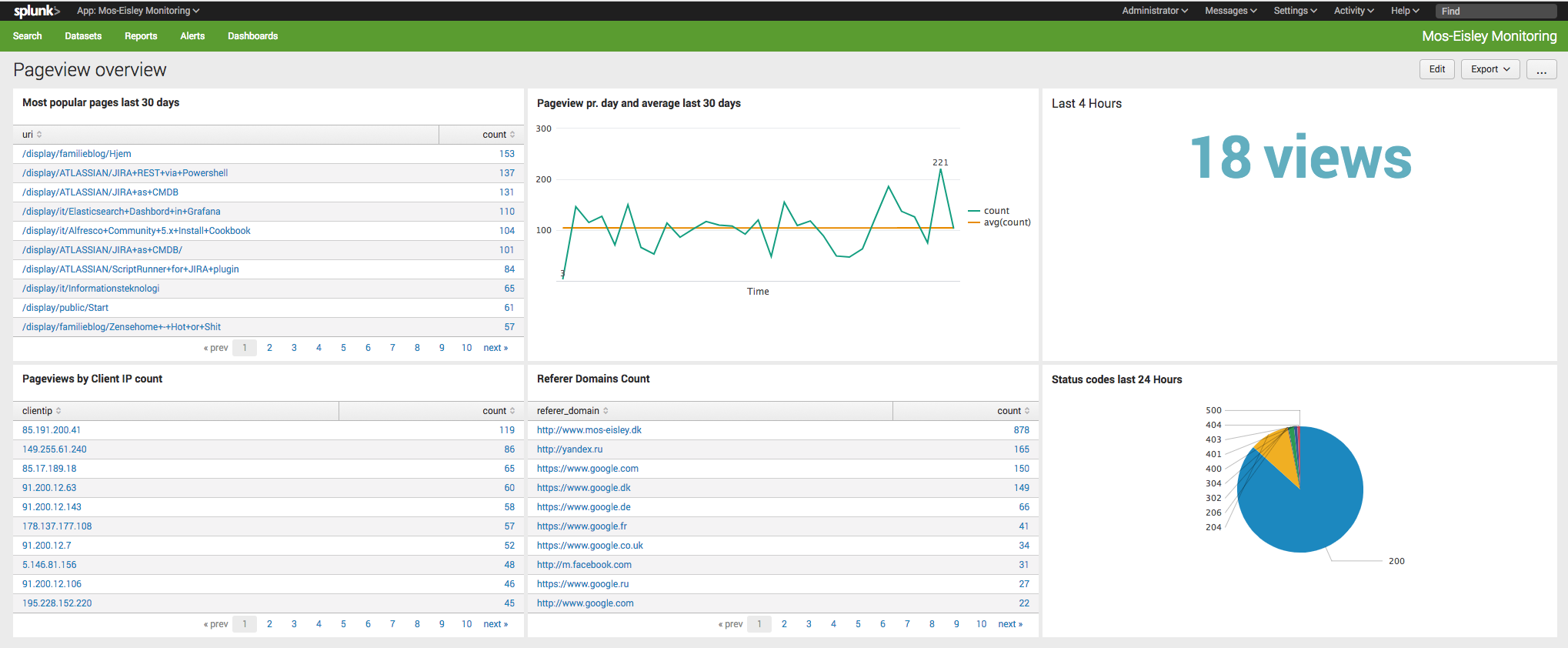
This little article is trying to find the "real user" browsing hits on my Homepage. In front of the homepage is an Apache2 acting as proxy.
All logs are gathered in Splunk. In the next part, "crawlers" is a synomyn for Robots, Crawlers and Spiders - hence non-live machines.
No valid Data Center license found
Please go to Atlassian Marketplace to purchase or evaluate Refined Toolkit for Confluence Data Center.Please read this document to get more information about the newly released Data Center version.
Step - Filter page views
First, we need to include what actually is a "view" and not REST, saving pages, uploading stuff etc. For Confluence, all views are in one of 2 forms:
(uri="*/display/*" OR uri="*/viewpage.action/*")
All other URI's are not relevant...
Step - Eliminate all "bots"
Looking into the log files, look at the User Agent string, often these have a Bot-like name, but nowadays many crawlers acts as a normal browser and are not identifiable via the User Agent.
So, we try to eliminate them with exclusions:
useragent!="*bot*" useragent!="*spider*" useragent!="*facebookexternalhit*" useragent!="*crawler*" useragent!="*Datadog Agent*"
Step - Eliminate Monitoring
Monitoring Tools monitoring can fill a lot in the logs; to control and identify these, I have ensured the monitoring tool is only monitoring at a special URL: /display/public/HealthCheckPage.
Hence, to exclude the monitring:
uri!="/display/public/HealthCheckPage"
Step - Eliminate hosts that has looked at robots.txt
To remove hits from IP-Addresses that have looked at robots.txt, I have created a lookup to a csv file.
So a scheduled Report is running hourly:
index=apache robots.txt clientip="*" | table clientip
Stored in the file robots_spiders.csv
root@splunkserver:/splunk/etc/apps/moseisleymonitoring/lookups# head robot_spiders.csv clientip "216.244.66.237" "77.75.76.163" "77.75.77.62" "216.244.66.237" "77.75.78.162" "216.244.66.237" "77.75.76.165" "37.9.113.190" "106.120.173.75"
To exclude these IP Addresses:
NOT [| inputlookup robot_spiders.csv | fields clientip]
Step - Eliminate all "hard hitting hosts"
As many crawlers use browser like User Agents and acts like real browsers, looking into my logs I see a large number of hits from them, so I have taken the assumption that more than 100 hits on the same URI within 30 days states that it is not a person using a browser.
So a scheduled Report is running daily:
index=apache AND host=moserver AND (uri="*/display/*" OR uri="*/viewpage.action/*") | stats count by uri clientip | where count>100
Stored in the file hard_hitting_hosts.csv
root@splunkserver:/splunk/etc/apps/moseisleymonitoring/lookups# head hard_hitting_hosts.csv uri,clientip,count "/display/ATLASSIAN/JIRA+as+CMDB/","188.163.74.19",125 "/display/ATLASSIAN/JIRA+as+CMDB/","37.115.189.113",138 "/display/ATLASSIAN/JIRA+as+CMDB/","37.115.191.27",121 "/display/ATLASSIAN/JIRA+as+CMDB/","46.118.159.224",101 "/display/public/HealthCheckPage","77.243.52.139",5732 "/display/slangereden/","5.9.155.37",118 "/display/slangereden/","66.249.64.19",140
To exclude these IP Addresses:
NOT [| inputlookup hard_hitting_hosts.csv | fields clientip]
To sum up - Conclusion
The final result is this splunk search:
(uri="*/display/*" OR uri="*/viewpage.action/*") uri!="/display/public/HealthCheckPage" useragent!="*bot*" useragent!="*spider*" useragent!="*facebookexternalhit*" useragent!="*crawler*" useragent!="*Datadog Agent*" NOT [| inputlookup robot_spiders.csv | fields clientip] NOT [| inputlookup hard_hitting_hosts.csv | fields clientip]
Gives a more correct Dashboard: