Humio is an alternative to app/log-parsers as splunk, Elasticsearch or Datadogs Log Management..
As I already have filebeat running against splunk, its easy to add output to cloud.humio.com after signing up for a free 2 GB/Day instance :
Humio has the same inputs (more or less) as Elasticsearch Bulk and Splunk HTTP Event Collector, making it an easy replacement.
output:
### Elasticsearch as output
elasticsearch:
# Array of hosts to connect to.
# Scheme and port can be left out and will be set to the default (http and 9200)
# In case you specify and additional path, the scheme is required: http://localhost:9200/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:9200
hosts: ["https://cloud.humio.com:443/api/v1/ingest/elastic-bulk"]
# Optional protocol and basic auth credentials.
#protocol: "https"
username: "anything"
password: "*********************************"
# Number of workers per Elasticsearch host.
worker: 1
compression_level: 5
bulk_max_size: 200
Ref: https://docs.humio.com/integrations/data-shippers/beats/filebeat/
Before Humio, my log collector in filebeat.yml looked like this:
-
input_type: log
paths:
- /var/log/apache2/www.mos-eisley.dk-*.log
document_type: apache
And it seems, that "document_type" becomes the parser selected in Humio. As Default parser for such Apache log files are "accesslog" I cloned that one to "apache"; but I could also choose to change the "document_type" in filebeat.yml:
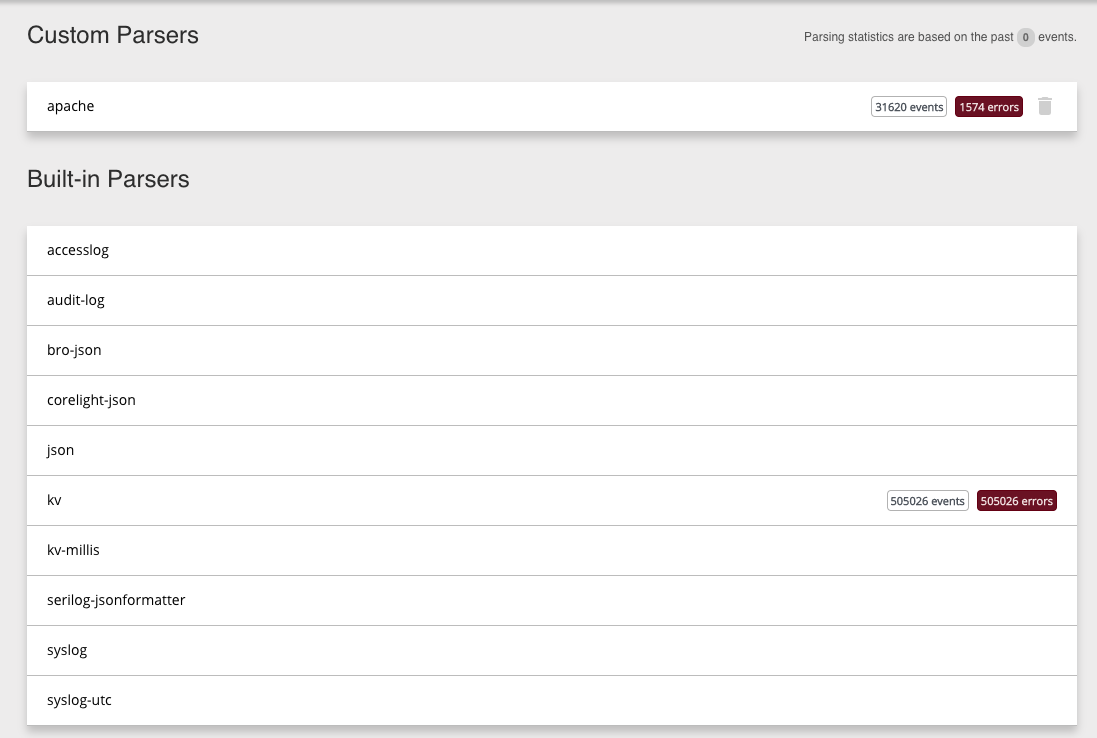
Do remember to add
queue.mem: events: 8000 flush.min_events: 1000 flush.timeout: 1s
To minimize the filling somewhat, I changes the filebeat.yml to:
-
input_type: log
paths:
- /var/log/apache2/*access*.log
document_type: apache